Yes, we love trying out the latest frontier model too. But in day-to-day project work, what matters most is control over costs, data, and availability. That's why we increasingly rely on open-weight models (models whose weights are publicly available) paired with open-source tooling. Here's what our setup looks like.
Nicolas Inden
Senior Consultant
Open models and tools are long past being a gimmick. They're a real, viable alternative, and a good complement to an existing AI setup.
What you’ll learn in this article
Frontier models: relevant, but in day-to-day project work, cost, data protection, and availability often take priority.
Three use cases: chat/expert models, agentic software engineering, product integration.
Setup: OpenWebUI + LiteLLM, inference from EU providers with no US roots.
Result: cost control, EU data, switch providers anytime – for little extra effort.
Content
I'll admit it: we've got them here too – the crowd that loves using the biggest, fastest, and best of everything. AI is no exception. And that's a good thing, because it's exactly that drive that keeps us on the cutting edge and means we always know what's technically possible in our projects.
AI is a very broad field. To make sure we're talking about concrete usage patterns and not just the latest model, our AI use so far breaks down into essentially three categories:
Chat for research, or using self-built "domain experts"
For all these areas, the well-known US providers (among others) give us convenient, polished tools, from ChatGPT to Claude Code to their respective API platforms. But now that AI use has grown up a bit, the focus is no longer just on using the biggest, fastest, and best model, but also on practical, legal, and financial considerations:
How are the costs of our AI usage developing?
Where is my data processed, and who ultimately has access to it?
Can I switch to another provider without much effort if the model I'm using is no longer available?
Considering just Anthropic and OpenAI, a user already ends up with four different accounts if they want to use all the services, because both Anthropic and OpenAI each offer a subscription (claude.ai and chatgpt.com) as well as an API offering (Claude Platform and OpenAI Platform). The subscription includes chat and agentic coding within quotas, but here too you can of course feed in more coins to break through the limits. The API offering is always billed pay-per-use per token. Keeping track of it all takes a bit of effort. Anyone who doesn't set notifications or limits on the API platforms will be surprised at how quickly the bill can climb there.
For standard subscriptions and typical project use, neither of these two providers can currently give a satisfactory answer to the data-protection question, because both offer EU-only data processing only on request – or not at all. In neither case is zero data retention offered, meaning the complete deletion of prompt and response data immediately after the response is delivered. They justify this with abuse-detection obligations. As a result, user prompts are sometimes stored for up to 30 days. At least, for paid use of their services, both providers commit not to use your data to train their models. In the world of open-weight models, EU data residency, zero data retention, and no training on your data are a given. There are plenty of such providers in the EU with no roots tracing back to the US.
Why would I want to switch my model at all? Well, for one, there might be a better or cheaper model elsewhere. Or maybe the model I've been using has been cut off. A prominent example: the now-lifted US government export restrictions on Anthropic's Fable and Mythos models. And GPT-5.6, too, currently has to pass a review before it can be made generally available. There's plenty of speculation about the real reasons behind these restrictions and delays, which we won't get into here. But it shows that availability isn't guaranteed. This situation is problematic in (at least) two respects:
When proprietary US models are subject to a restriction, it affects every provider of those models. Not only can Anthropic itself no longer offer them – neither can providers like AWS Bedrock. The models are effectively unusable. Open-weight models are immune to this: once published, the weights can be downloaded by anyone and the model can be run.
Switching away from the proprietary frontier models to an alternative may technically be just an API change, but functionally it can significantly affect the results of your AI application – so much so that even painstakingly crafted prompts have to be reworked completely to get similar results. With open-weight models, there are many providers offering the same models. If I run into problems with one provider, I switch to another – but the model and its behavior stay the same.
To keep all of this under control, we'd like to introduce a system built from open-source software and open-weight models that addresses the three categories and the aspects mentioned above.
The Tooling
The first thing to figure out is what we want to "run" ourselves and what we want to use from existing providers. While running a server with the right software for chat and API access is still fairly manageable, AI inference requires more thought. Open models come in all sizes, from "runs on my machine" to "needs more than 4 GPUs". If we assume we want to use large, modern open-weight models that can compete with GPT and Opus, then as of this article's publication date (July 5, 2026) we inevitably land on GLM-5.2 and K2.7. At 744B and 1T parameters, the required hardware is considerable. The recommended setup for GLM-5.2 with fp8 quantization is 8x Nvidia H200, and that's just for basic operation, before you even count concurrent users.
The sweet spot we currently run is:
Self-host central access to chat and API
Source AI inference from EU providers
We cover the three main use cases with the following tools:
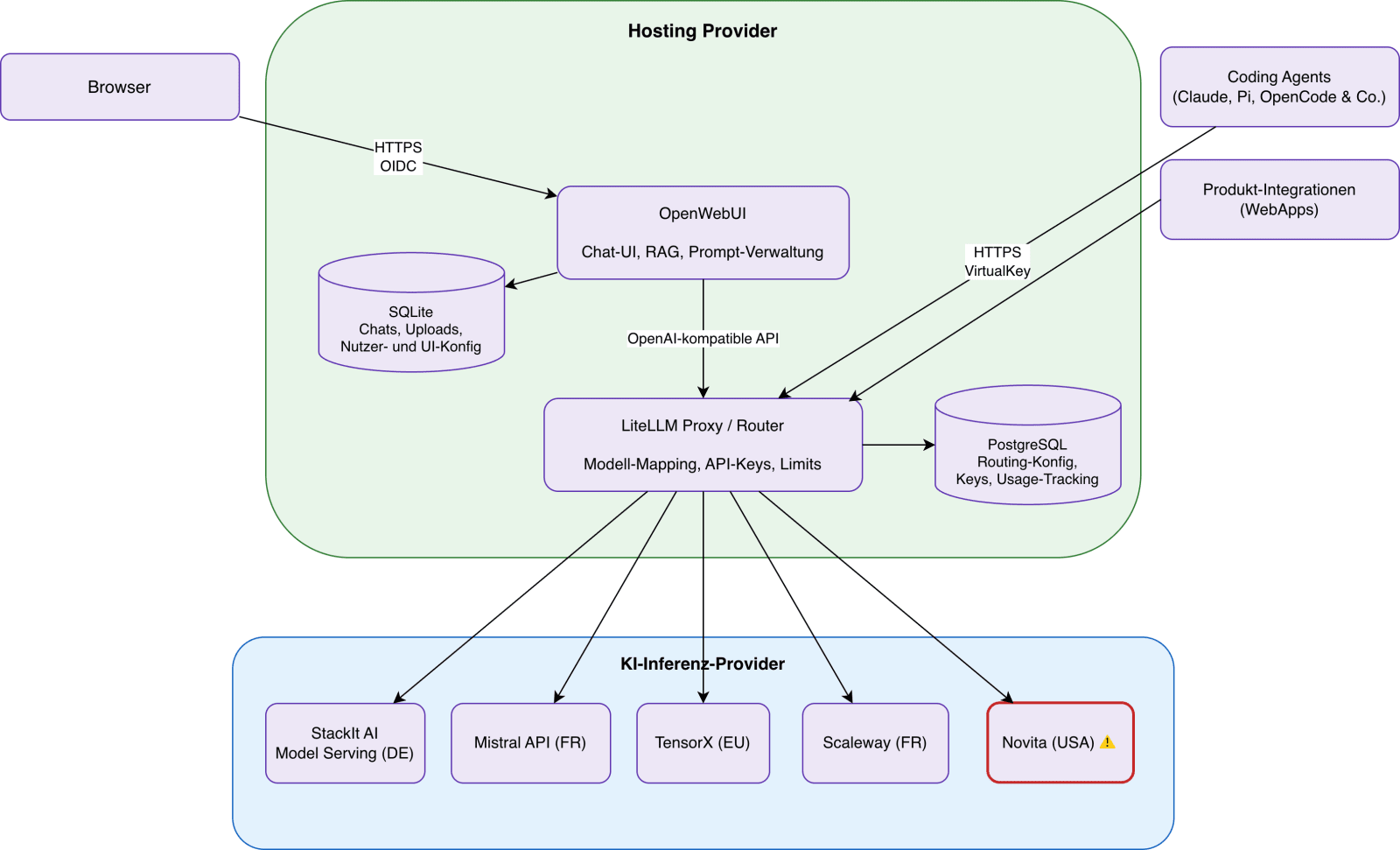
In our specific case, the overview of the overall system looks like this:
An overview of the systems and components in use
If the system isn't intended solely for your own private use but also processes other people's personal data, it's important to have DPAs (data processing agreements) in place with all data-processing parties. Essentially, that means the hosting provider for OpenWebUI and LiteLLM and the AI inference providers.
You also shouldn't underestimate the ongoing maintenance involved: models get updated, providers change prices or restrict their offerings, and virtual keys along with their budget limits need to be reviewed regularly. The extra effort is manageable, but it isn't zero.
OpenWebUI for chat und expert models
OpenWebUI offers a convenient web interface similar to those of ChatGPT or Claude. The difference: behind the scenes, it can use open AI models from a wide range of providers, whether self-hosted or via a provider's API. Beyond simple chat, OpenWebUI offers a whole range of features that let you bring in additional knowledge.
Noes let you capture text or speech and search it from within your chats
Knowledge lets you load data into a vector database and access it via RAG
MCP lets you access a wide variety of available information sources via MCP
With these features, I can build myself a knowledge hub, whether project-specific or company-wide.
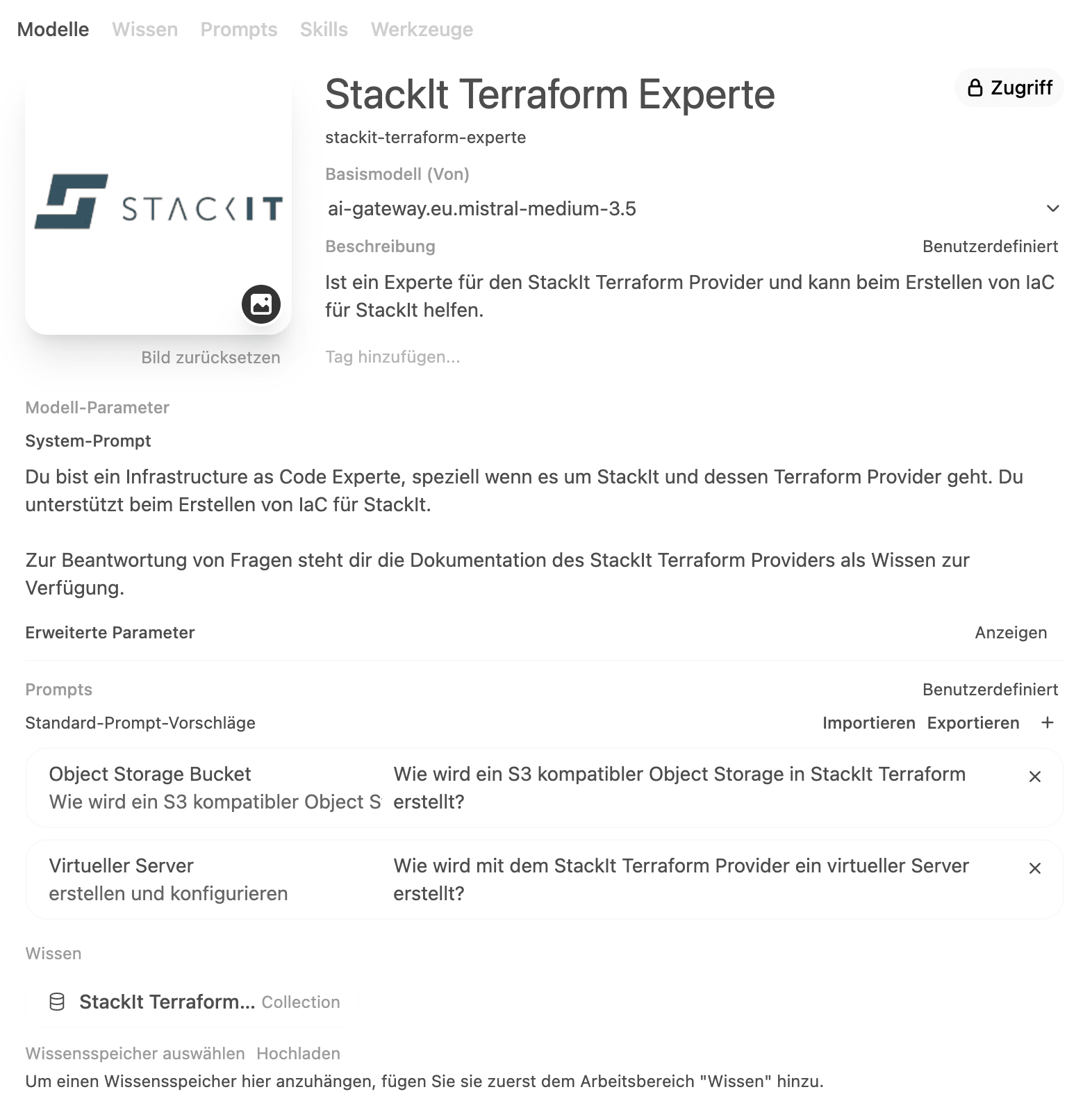
For example, the knowledge feature lets you build an expert on a particular topic. We tried this out with StackIt's Terraform provider. The documentation for it is freely available as a collection of Markdown files and can be loaded as "knowledge" into OpenWebUI. If we now create a new [model in OpenWebUI, we can link a base model like GLM-5.2 to knowledge from OpenWebUI. We'll call this new model, for example, "StackIt Terraform Expert". Together with a suitable system prompt for the new model, we can now ask questions about generating Terraform code for StackIt.
Another scenario is accessing internal company information. Via MCP, models in OpenWebUI can be connected to sources like OpenCode, Jira, and Confluence. So the ever-popular question of where the current slide template lives – and much more – can now be answered by the AI too.
There are also good mobile apps for OpenWebUI, by the way, that make your own AI system easy to use on the go. I've had good experiences with the iOS app Conduit, for instance.
Technical details
Even though the token volume via OpenWebUI is vanishingly small compared to using coding agents, we still want to track this consumption too. So we create a dedicated virtual key in LiteLLM that we use to supply OpenWebUI with AI models. This also lets us transparently switch the provider behind an AI model for OpenWebUI.
LiteLLM for coding agents and product integration
Wherever AI needs to be accessed via an API, LiteLLM comes into play as a proxy and router. Consolidating all AI API calls through LiteLLM gives us the following advantages:
Central cost and usage tracking
Transparent swapping of a model's provider
Individual, project- or application-specific budgets
One and the same base URL, no matter which model I want to use
LiteLLM actually offers a whole lot more, but those are the most important ones in this context for now.
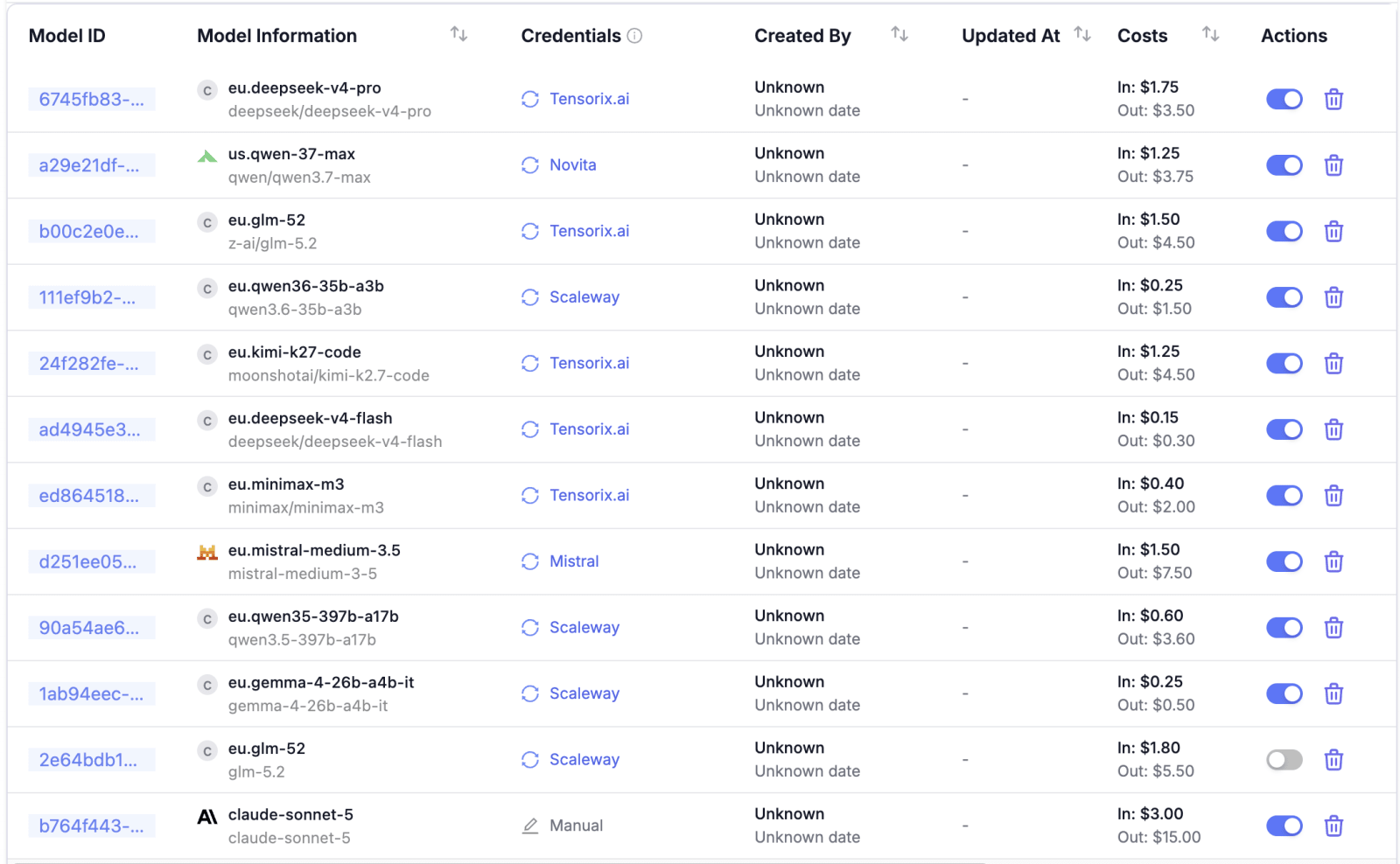
List of models configured in LiteLLM
Setup within LiteLLM begins with creating the desired models and provider credentials. If the provider is already known to LiteLLM, as with Novita for example, then a lot of information about the model is filled in automatically. This mainly covers the prices for input and output tokens and cache reads. Providers can also be created manually, in which case the pricing information has to be maintained manually on the models.
To be able to use the models you've just set up via LiteLLM, you need virtual keys (API keys) in LiteLLM. These can be assigned to a user, or to a user in the context of a team. This makes sense when you want different budget limits per project.
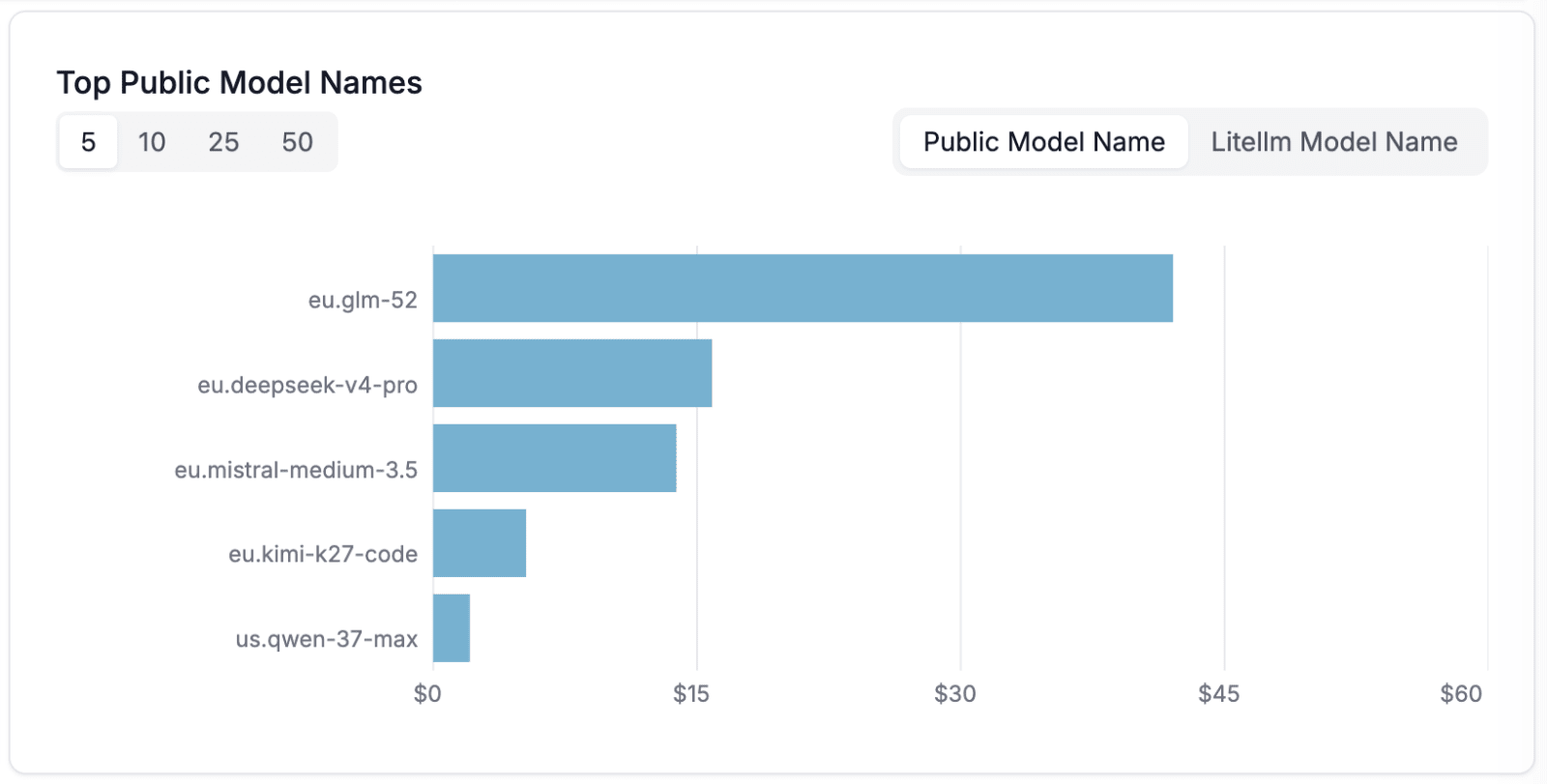
Chart of the most-used models by cost
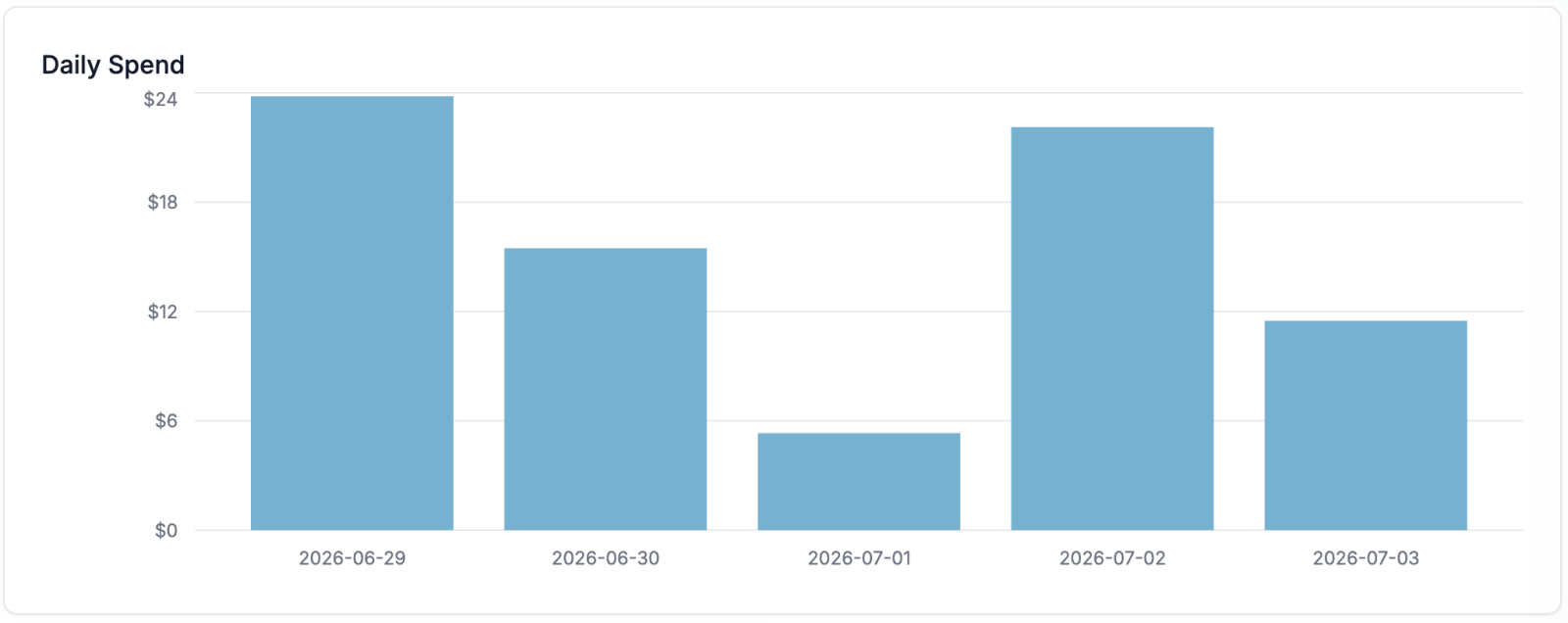
Chart of daily costs
From the tokens consumed and the pricing information, LiteLLM then generates various charts that present costs and usage sorted from many different angles, for example:
Cost per virtual key
Cost per model
Cost per day
Cost per team
It's also worth mentioning here that Anthropic and OpenAI models can be used "through" LiteLLM as well. This works even for users who have a subscription. For this, LiteLLM offers two functions, "Forward client headers to LLM API" and "Forward LLM provider auth headers", which ensure that the separate headers used by the coding agents to log in to Anthropic and OpenAI are passed through.
AI inference via API providers
As we've researched and tested various inference API providers, the picture has changed significantly over the past few months. Whereas at the start of this year it was mainly US providers like [Novita](https://novita.ai/de) that offered up-to-date open-weight models promptly, there are now several EU providers with no US roots that also carry current models with little delay. Good places to start are, for example:
Even within Germany, StackIt and IONOS offer AI inference APIs, though in our most recent tests only smaller or outdated models were unfortunately available there.
Usage
Here are a few practical notes on connecting coding agents and applications to LiteLLM. We'll also look at how to create an expert model in OpenWebUI.
Using coding agents with LiteLLM
Here are a few examples of how coding agents can be connected to LiteLLM. The model ID should always be chosen as it was defined in LiteLLM (cf. the screenshot above).
Claude Code
Claude Code is configured in `~/.claude/settings.json`. The content should look roughly like this:
LiteLLM provides both an OpenAI-compatible API and an Anthropic Messages-compatible API, so you can use the existing libraries as long as you adjust the base URL and the API key.
In both cases, the requests are forwarded by LiteLLM to the connected provider for the model chosen here as an example, `eu.mistral-medium-3.5`.
Connecting OpenWebUI to LiteLLM
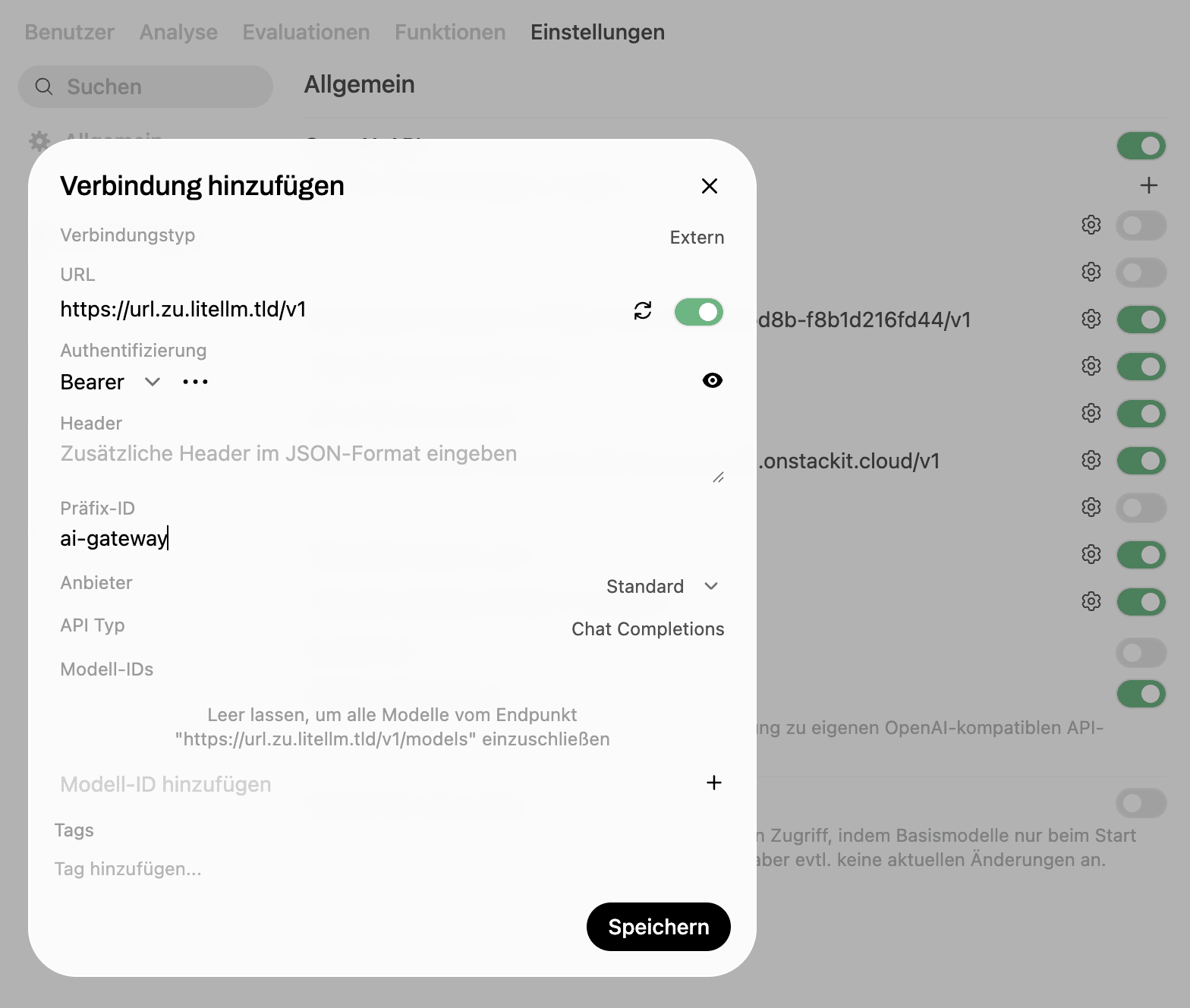
So that our chat, research, and expert-model solution OpenWebUI can also use the AI models we provide via LiteLLM, we need to add our LiteLLM server as a "connection". This is done under
"Admin Settings" - "Settings" - "Connections"
Adding a connection from OpenWebUI to LiteLLM
For this, we use the URL of our LiteLLM server followed by /v1 and a virtual key we created for this in LiteLLM beforehand.
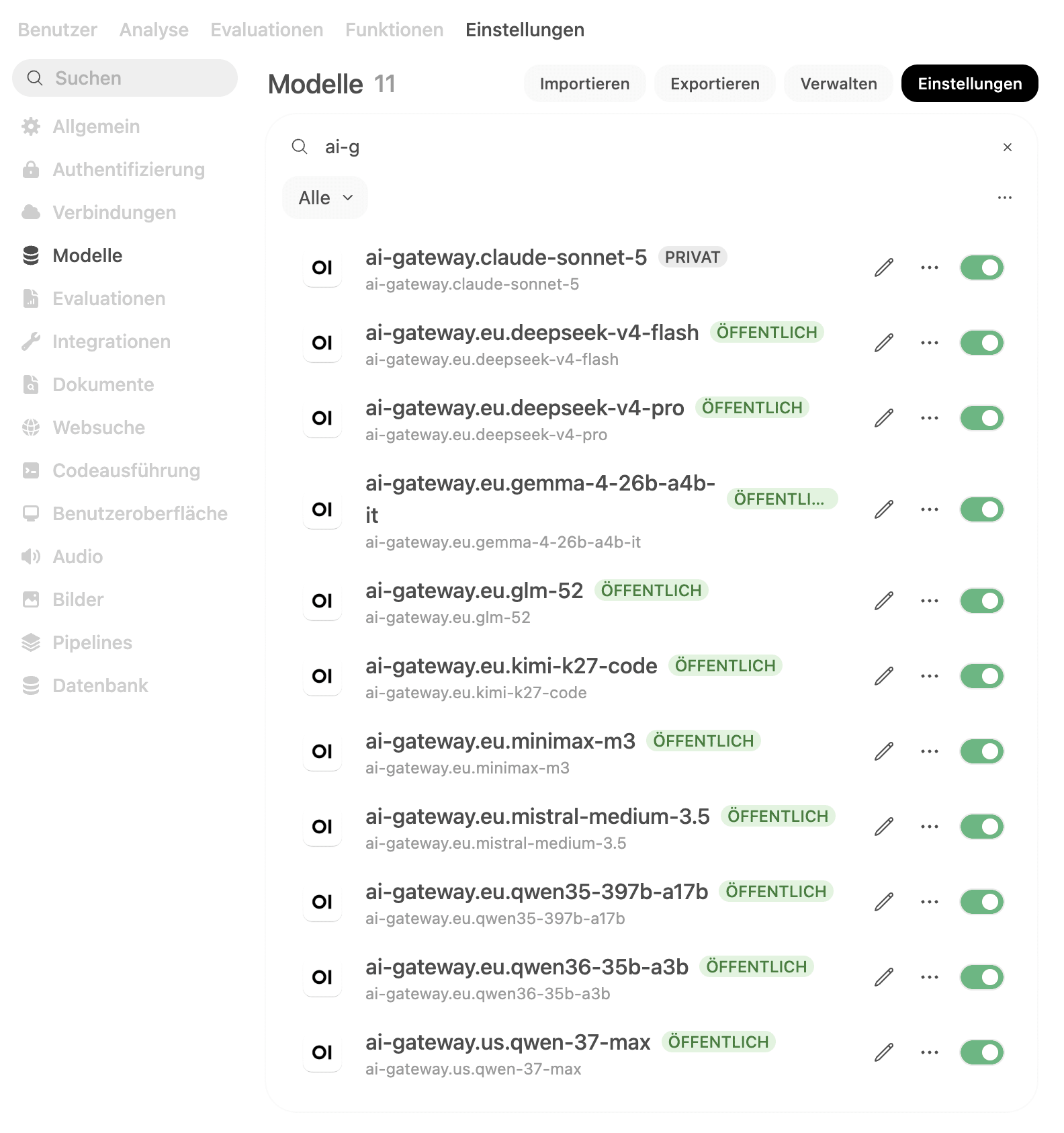
List of models provided by LiteLLM
Under `"Admin Settings" - "Settings" - "Models"` we now see our models displayed and can use them in OpenWebUI.
Expert models in OpenWebUI
As mentioned at the start, OpenWebUI lets you bring in external knowledge via RAG or MCP. Let's walk through this step by step, using the "StackIt Terraform Expert" mentioned earlier as an example, with a knowledge base (RAG).
It's likewise possible to connect such an expert to a knowledge source via OpenAPI or MCP.
Step 1: Obtain knowledge
First, we need the knowledge base. The StackIt Terraform provider is maintained in an open GitHub repository, which also contains the documentation in Markdown files. So we first clone the repository:
The docs are now in the directory ./terraform-provider-stackit/docs.
Step 2: Create "Knowledge" in OpenWebUI
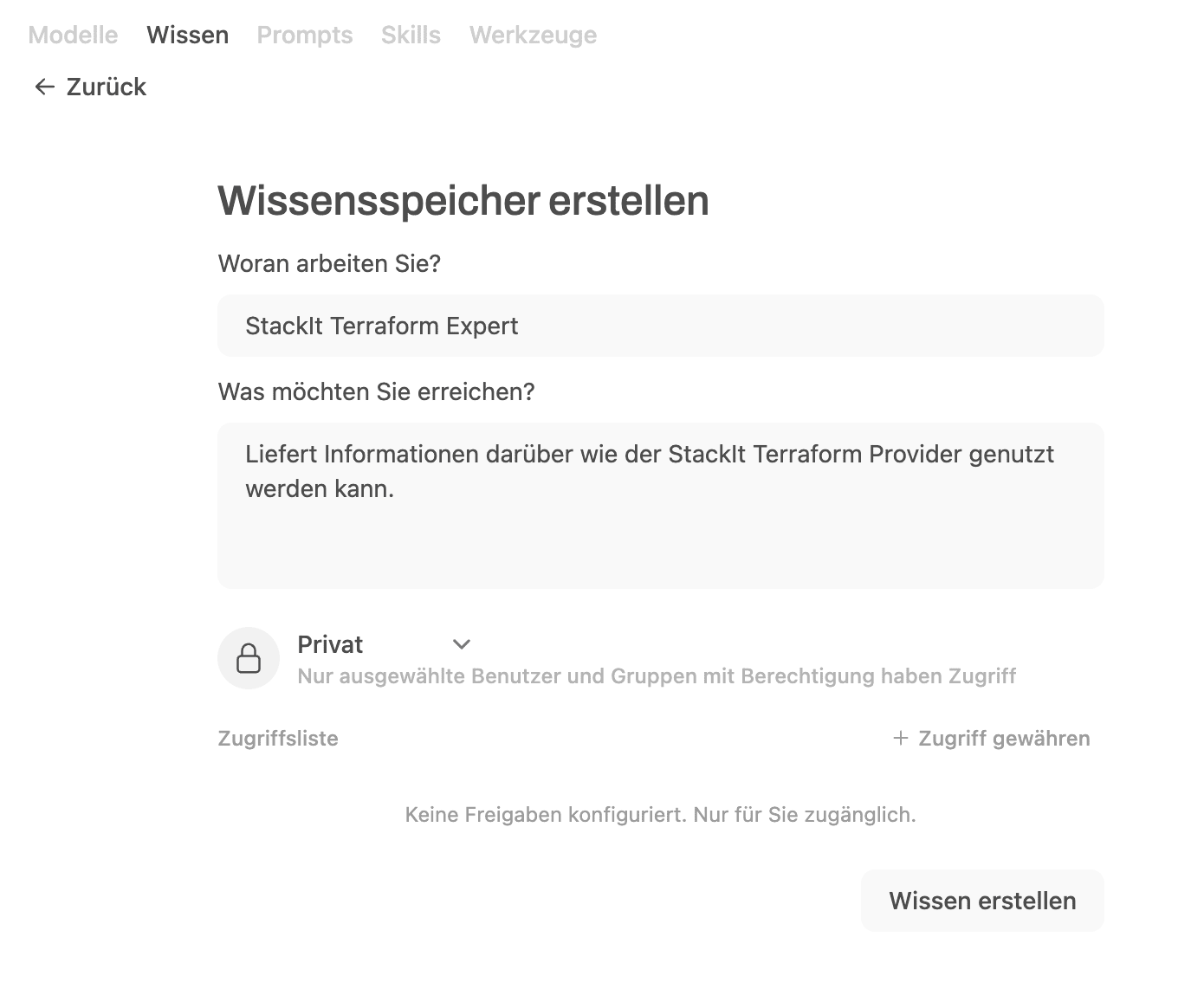
Creating a knowledge base
Via "Workspace" - "Knowledge", a new knowledge base is created and given a suitable name and description.
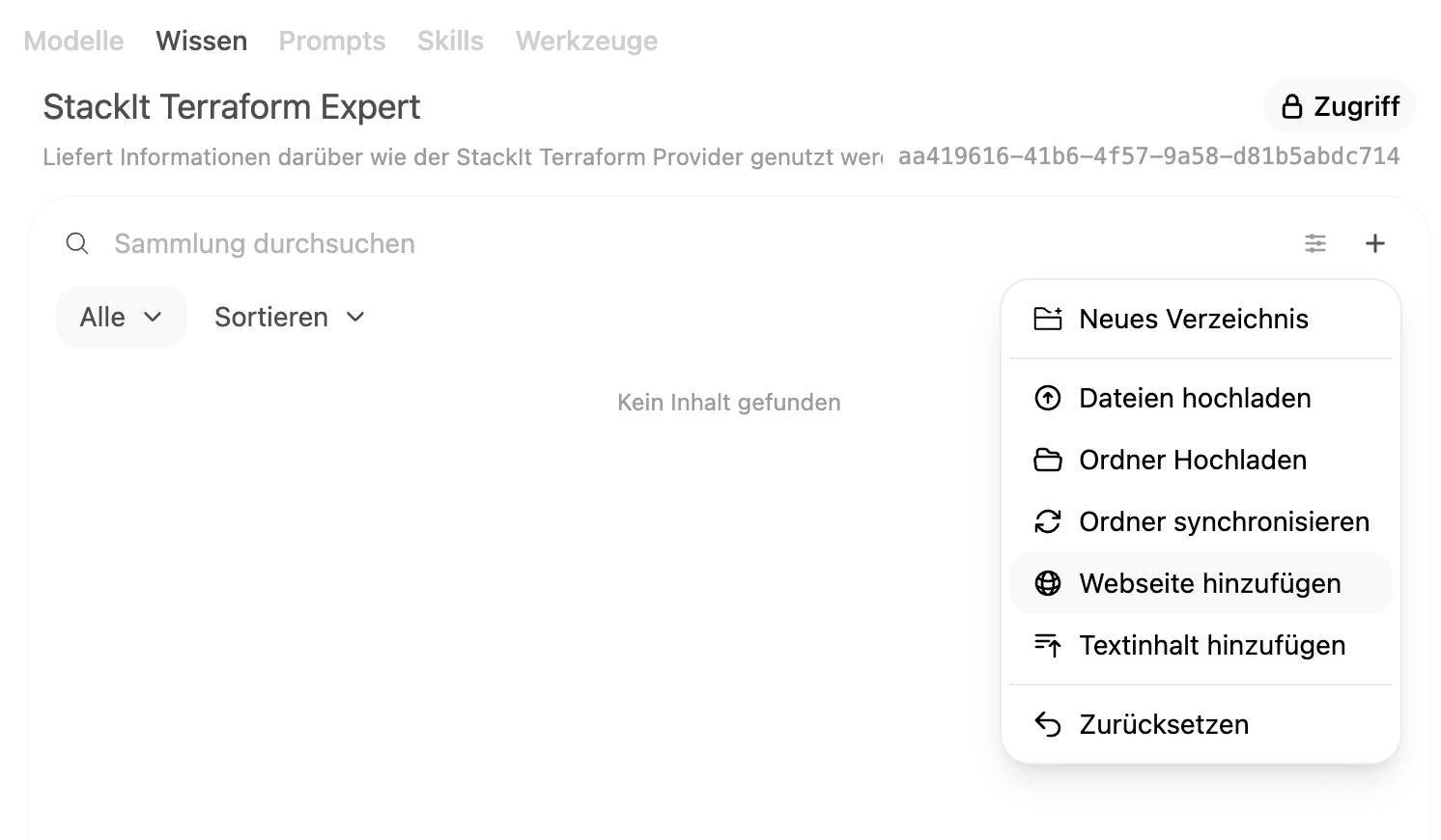
Adding knowledge
After creating it, we now open this knowledge base and upload the docs folder from the repository via "Upload folder".
The knowledge base can now be given to a model as base knowledge, or included in any chat via StackIt Terraform Expert.
Step 3: Create a model and link it with knowledge
We now create a model that automatically uses the previously created knowledge.
Erstellen eines Expertenmodells
For this, we provide the following information:
Model name
Base model(e.g. eu.mistral-medium-3.5)
System prompt
(optional) Default prompt suggestions
Knowledge base
The model is now ready to use and automatically draws on the knowledge uploaded earlier. Under the hood, this uses RAG, whose behavior can also be fine-tuned in detail under "Admin Settings" - "Settings" - "Documents".
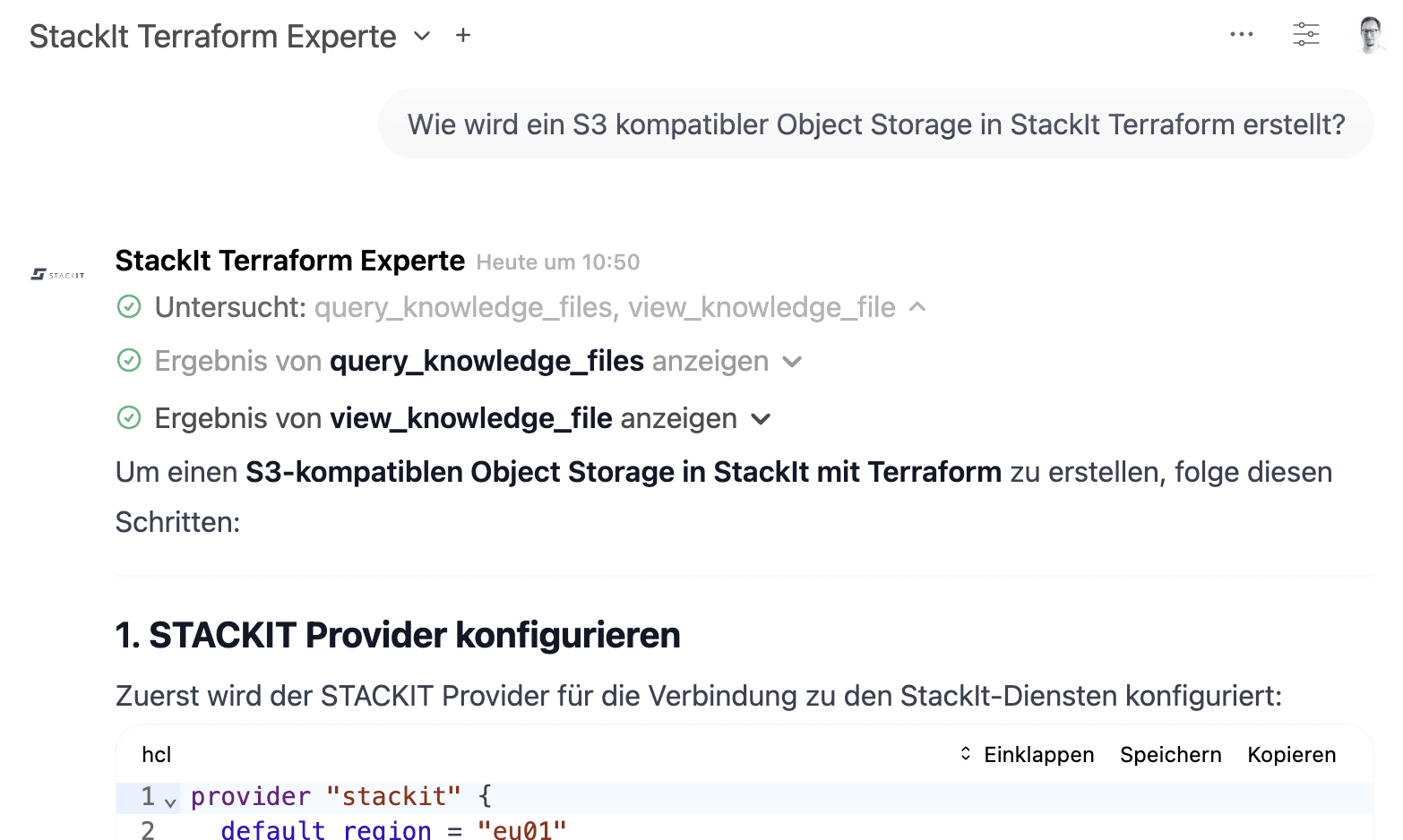
Step 4: The first test
We now test the expert we've just created:
Test run with the newly created expert model
From query_knowledge_files and view_knowledge_files, you can see that OpenWebUI uses the corresponding tools to search the existing knowledge for answers to the question asked.
Conclusion
Yes, we're still the crowd that loves trying out the biggest, fastest, and best. That won't change – and that's a good thing, because it's the only way we know what's really possible right now. But looking at open-weight models and open-source tools has shown us something: with open-source software and open models, we can get pretty similar results. Cheaper. More independent.
In our day-to-day work, a fairly simple system has proven itself: OpenWebUI for chat and expert models, LiteLLM as a proxy for coding agents and product integrations, and behind them EU-based providers where we at least feel good about data protection and availability. The big advantage? We can switch providers without our agents or applications noticing a thing. That's not only practical, it's also enormously reassuring when yet another frontier model is briefly unavailable or new terms crop up.
That doesn't mean we're leaving Claude, GPT, and co. behind. Quite the opposite: for many tasks they're still the first choice. But anyone using AI seriously today shouldn't put all their eggs in one basket. Open models and tools are long past being a gimmick; they're a real, viable alternative, and a good complement to an existing AI setup.
Nicolas Inden
Senior Consultant
Nicolas Inden
Senior Consultant
Nicolas is a Senior Consultant at INNOQ, bridging business and technology. He specializes in privacy-friendly AI integration and sovereign infrastructure, helping organizations run digital solutions independently and sustainably.
Nicolas Inden
Nicolas is a Senior Consultant at INNOQ, bridging business and technology. He specializes in privacy-friendly AI integration and sovereign infrastructure, helping organizations run digital solutions independently and sustainably.
Sovereignty Review
You know your dependencies. We help you assess what they mean.